正式使用 SVC Fusion
TIP
新版本使用启动器来下载和更新本体
1:下载和部署
获取整合包链接后进入网盘下载(目前 SVCFusion 使用 夸克网盘 发布)
整合包本体如下(该目录在 启动器目录/project 下):
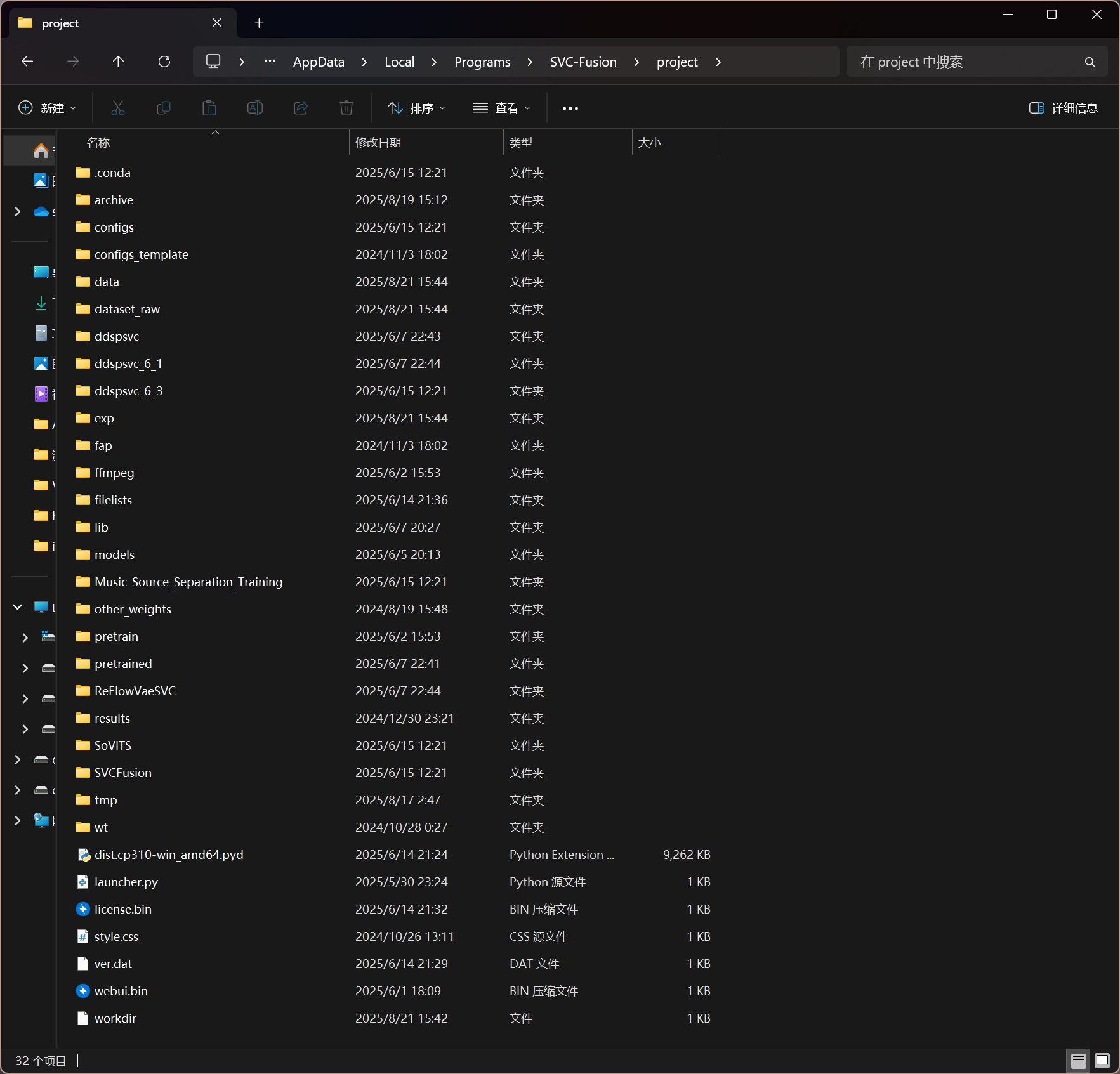
文件结构说明
| 文件夹 | 说明 |
|---|---|
| exp | 工作目录 |
| archive | 训练归档文件夹 |
| models | 已训练模型文件夹 |
| dataset_raw | 原始数据集文件夹 |
| data | 可用于训练的数据集存放位置 |
| tmp | 数据处理临时文件夹 |
2:SVC-Fusion,启动!
在启动器中点击启动按钮
启动可能需要等待一段时间。
出现提示框后,点击我同意,进入网页。
此时 cmd 控制台大概是这样的(使用 Fusion 时请勿关闭控制台!)
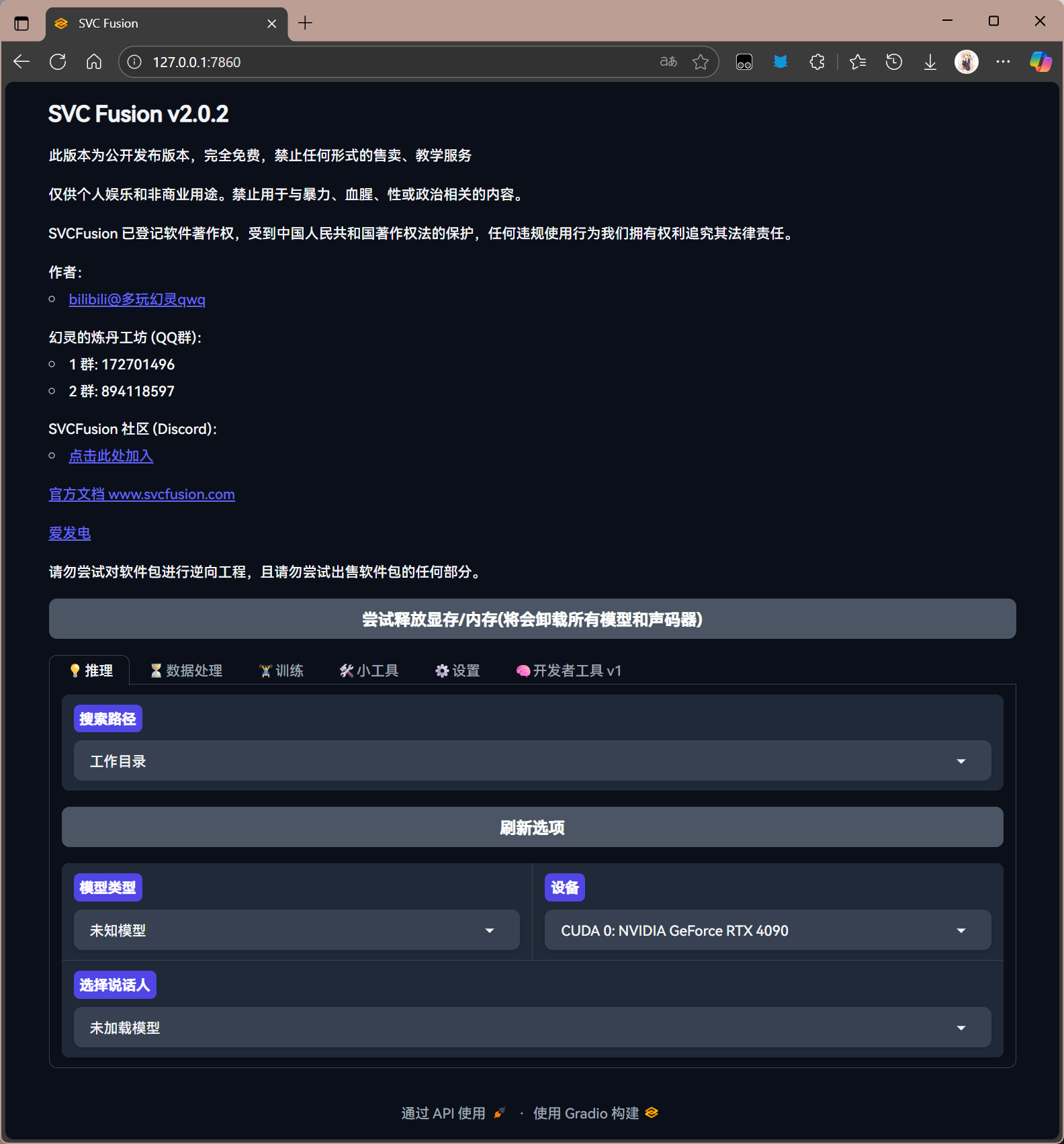
浏览器将自动打开网页,如下
TIP
推荐使用 Edge、Chrome 浏览器打开网页,并关闭网页翻译和加速器。
打开 webui 的过程中可能会出现若干警告,具体请详见文末的常见报错。
3:预处理
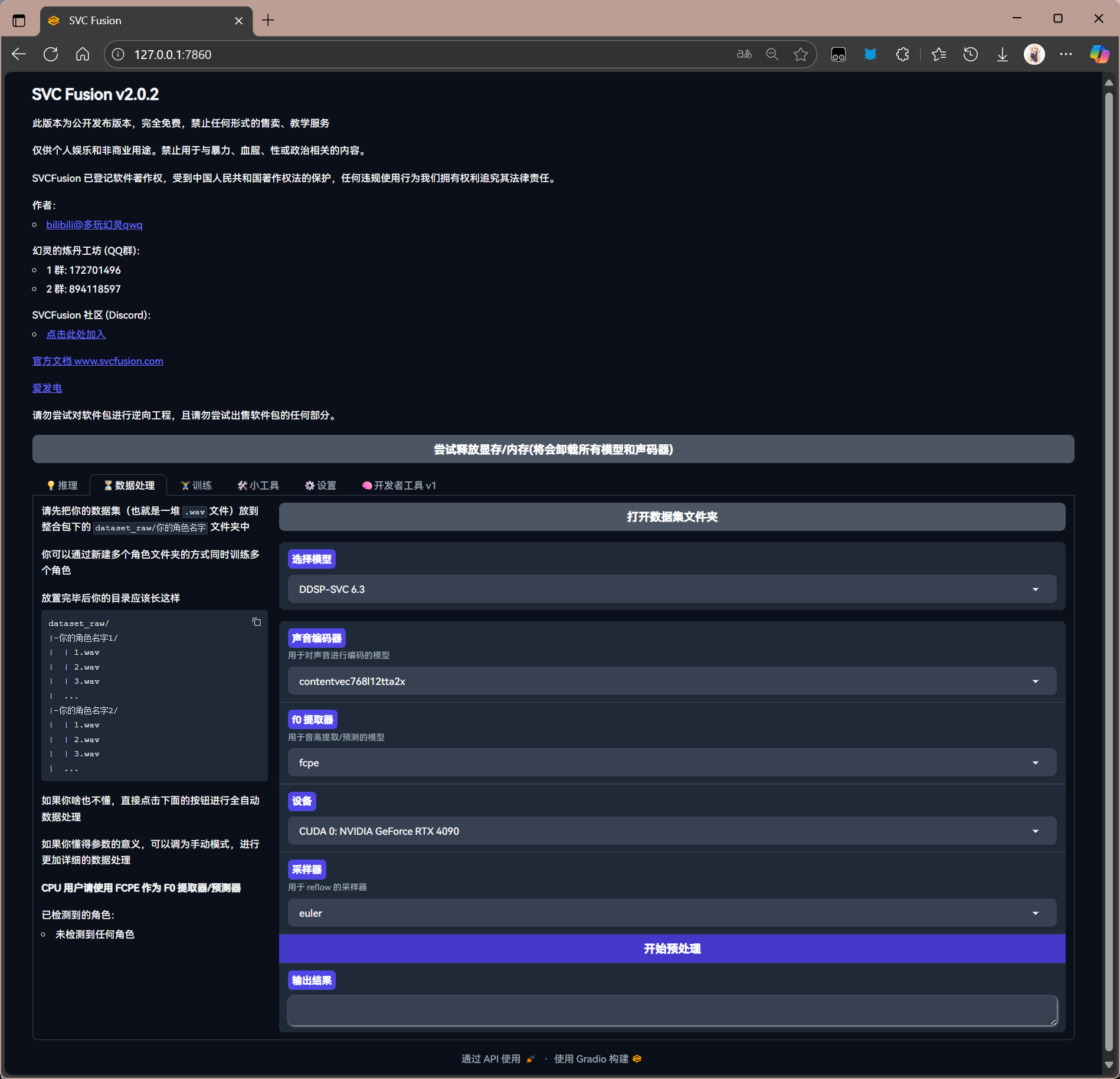
点击“打开数据集文件夹”进入 dataset_raw 文件夹
将准备好的数据集打包成文件夹放入此处,注意文件结构
dataset_raw/
|-你的角色名字 1/
| | 1.wav
| | 2.wav
| | 3.wav
| ...
|-你的角色名字 2/
| | 1.wav
| | 2.wav
| | 3.wav
| ...TIP
如果是单说话人,你的 dataset_raw 文件夹里面应该是这样的
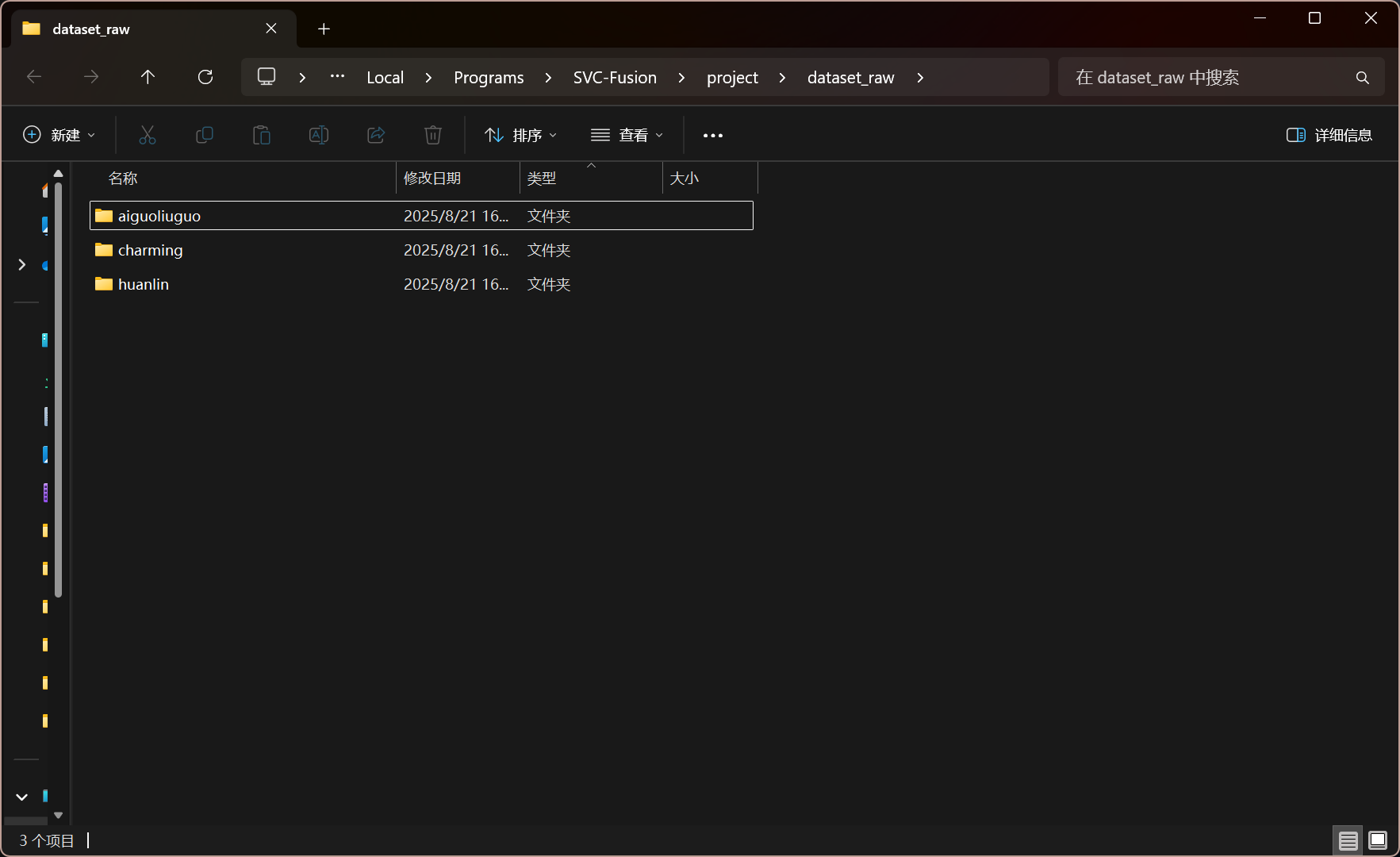
如果是多说话人,你的 dataset_raw 文件夹里面应该是这样的
数据集文件夹里应当是这样的 所有音频都不需要手动切片,直接放入长音频即可。
注:数据集命名若包含 特殊字符或中文 则 可能 在处理时发生报错,可使用未鸟的批量重命名工具进行修正。所有音频都不需要手动切片,直接放入长音频即可。
为了能够直观地教学,本次以单说话人进行示范。
回到网页,选择数据处理,进行预处理
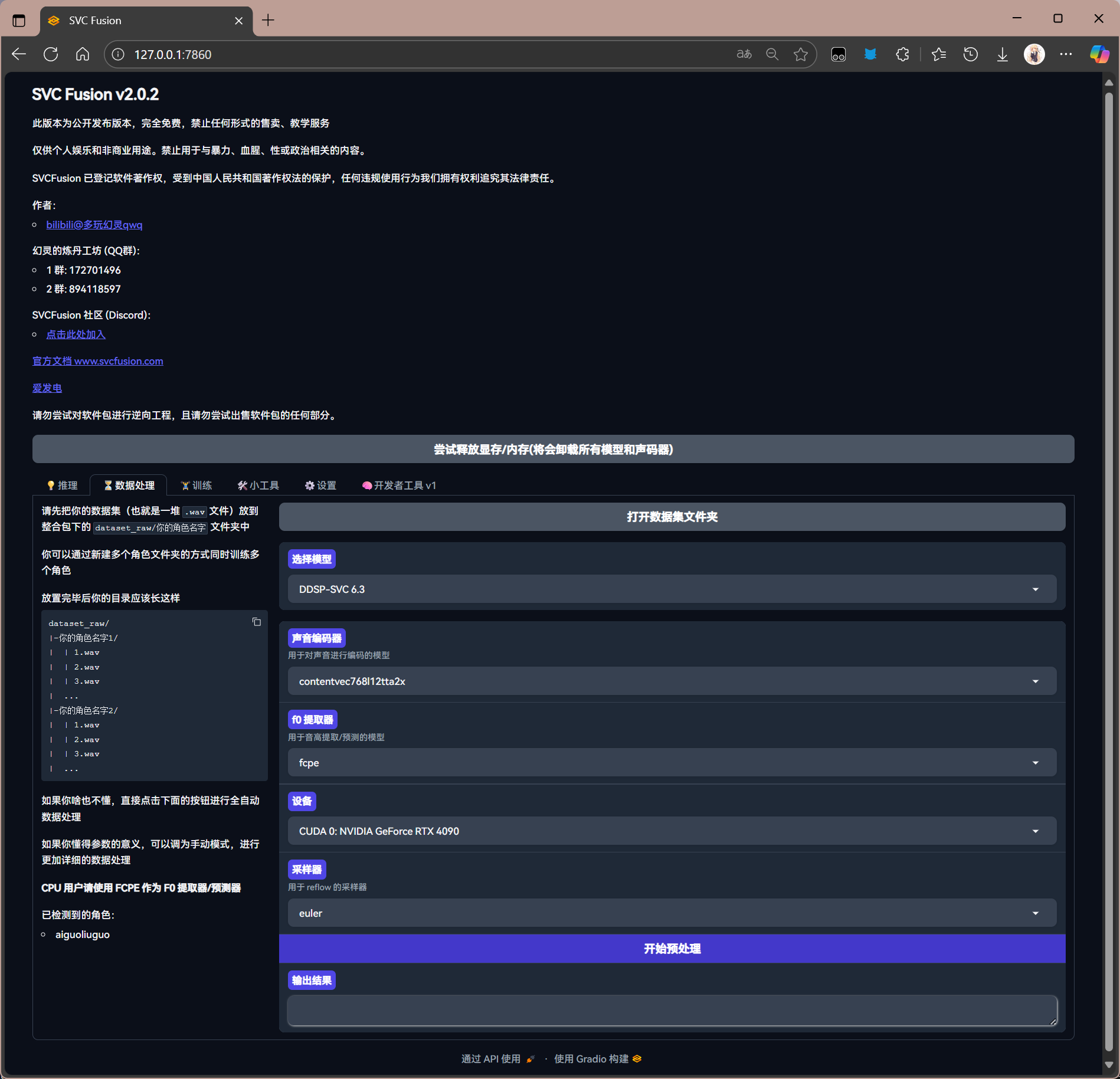
选择需要的算法(算法选择参考前文)
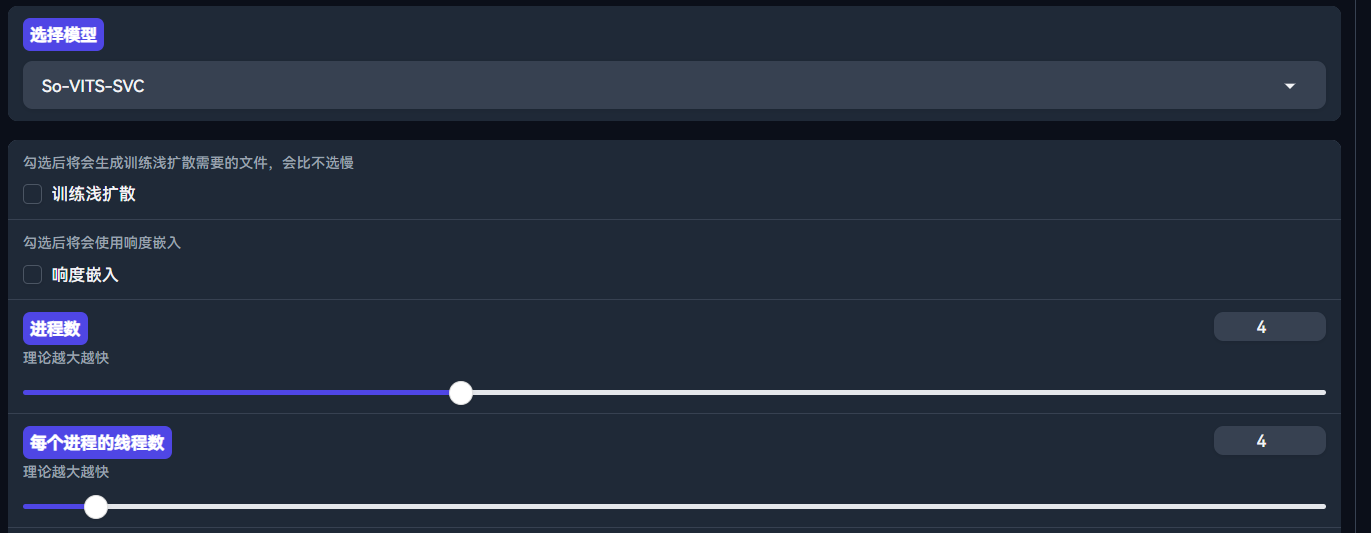
若选择 sovits,则另有几个选项,按需勾选
选择声音编码器(目前仅支持 768)

选择 F0 预处理器(通常为默认)

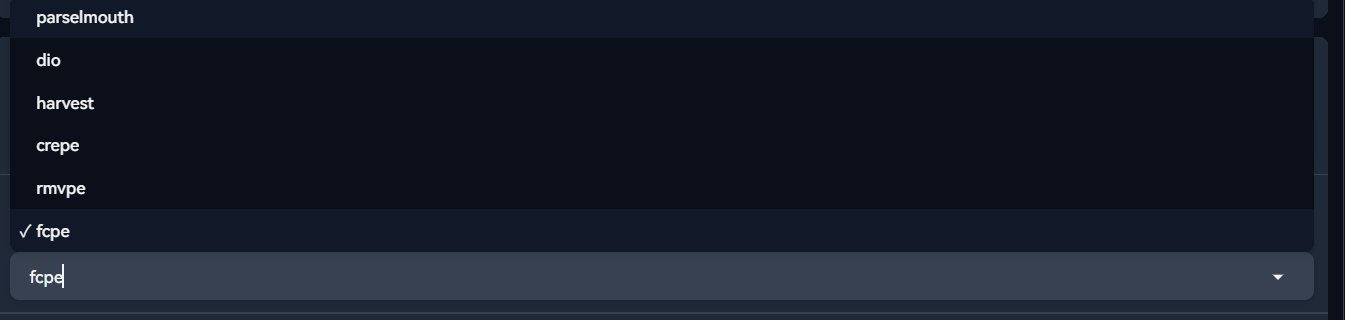
选择设备进行训练

然后选择用于 reflow 的采样器

选择完成后,点击”开始预处理“进行预处理

预处理完成
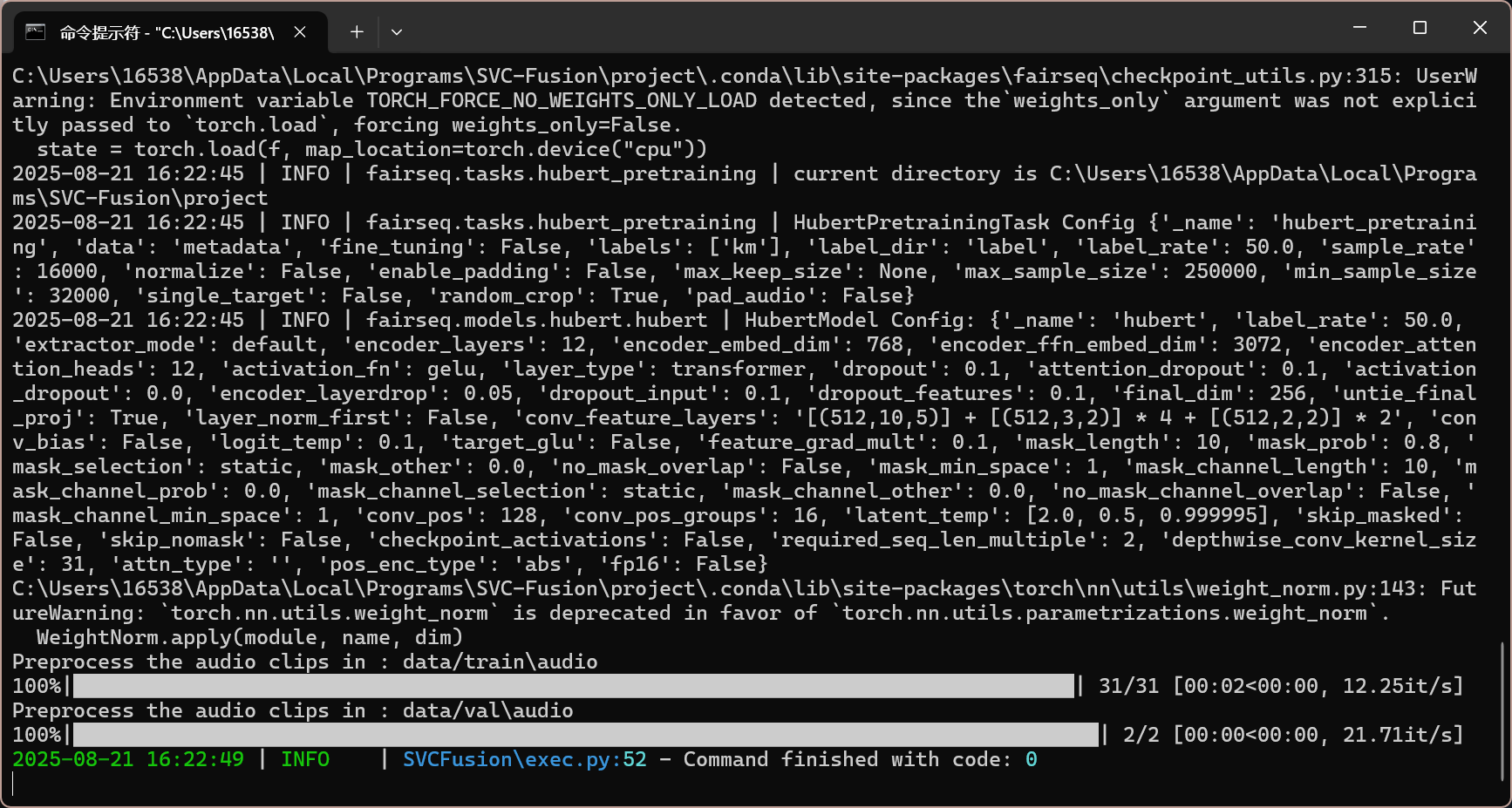

注:本教程以 ddsp6.3 为模型,其他算法的预处理/训练/推理界面略有不同,但操作逻辑相似。
4:训练
点击进入训练界面
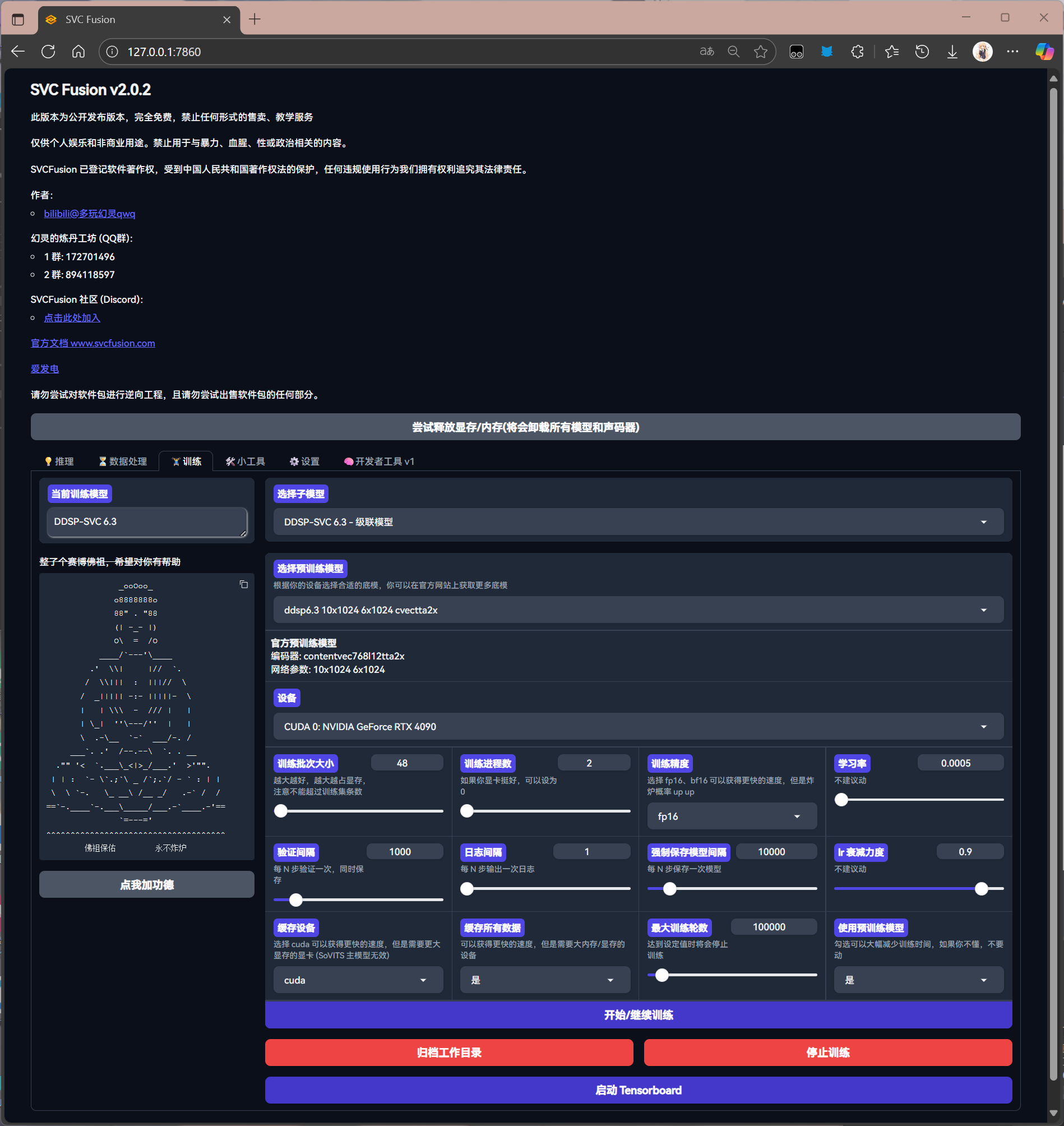
选择参数(一般为默认参数,默参也能用)
以下为训练参数详解:
| 参数名称 | 说明 |
|---|---|
| 训练批次大小 | batch_size(bs),越大越占显存,注意不能超过训练集条数。根据显存酌情调整,建议默认 |
| 训练进程数 | 如果你显卡较好,可以设为 0,会提升速度但不影响质量 |
| 训练精度 | fp32(单精度)、fp16(半精度)、bf16(混合精度),fp16可以获得更快的速度和更低的显存占用,但是炸炉概率 up up |
| 验证间隔 | 每 N 步验证一次,同时保存。 |
| 日志间隔 | 每 N 步输出一次日志。 |
| 强制保存模型间隔 | 每 N 步保存一次模型。 |
| lr 衰减力度 | 建议默认 |
| 缓存设备 | 选择 cuda 可以获得更快的速度,但是需要更大显存的显卡 (SoVITS 主模型无效),选择 cpu 则载入内存,减小硬盘 io 压力 |
| 缓存所有数据 | 若内存和显存较小则建议关闭,建议默认 |
| 最大训练轮数 | 建议默认 |
| 使用预训练模型 | 是否调用底模。建议默认 |
确定参数后点击“开始/继续训练”开始训练

等待弹出训练 bat
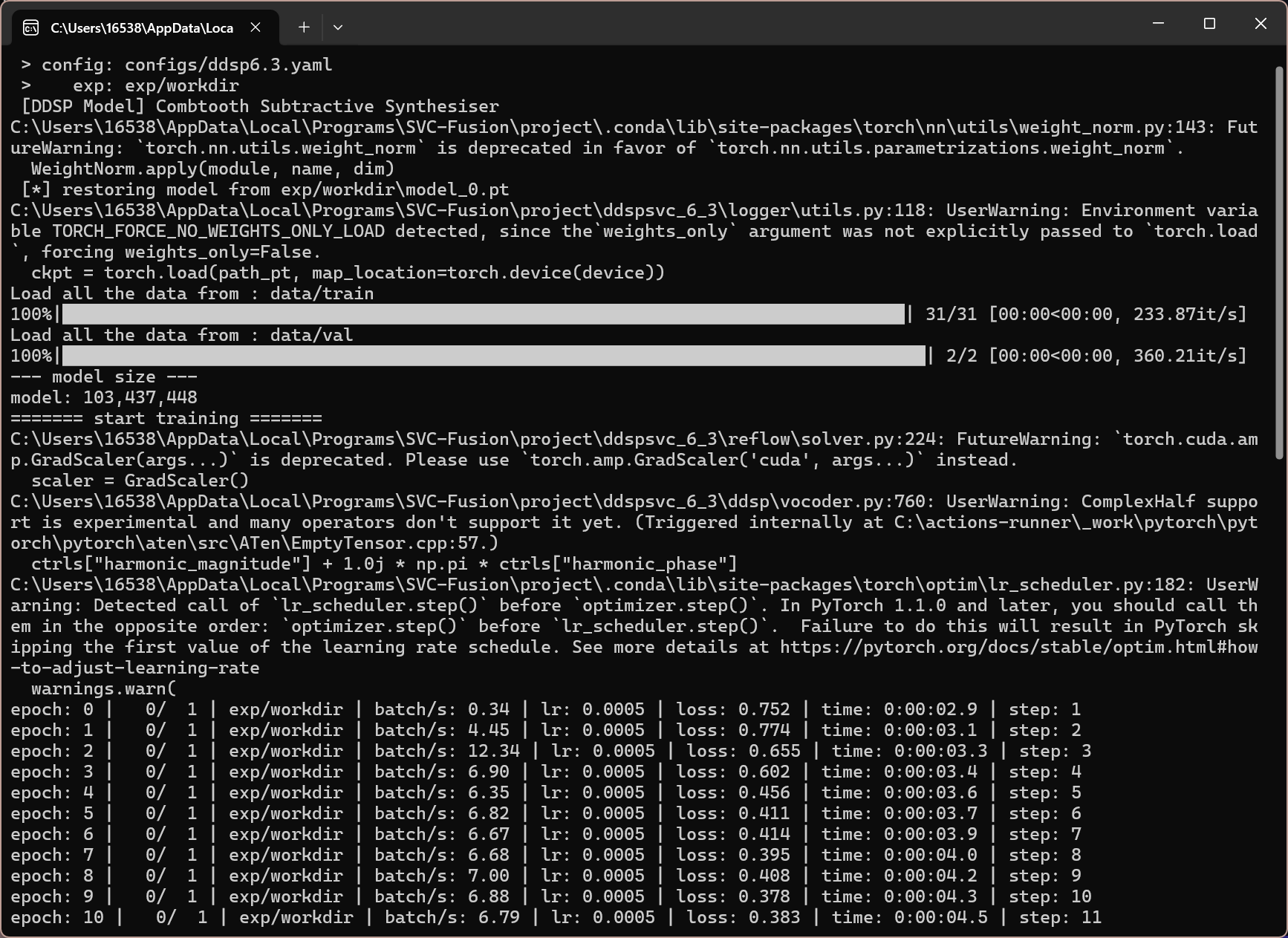
训练时长与数据集时长、质量、算法、预测器、bs、lr、GPU 相关,因此一般建议每 100-500 步(step)停下进行试听。使用 DDSP6.3 甚至更少
注意:不要迷信步数和 loss,无论哪个算法都不是炼的越久越好的!

结束、暂停训练请按停止训练
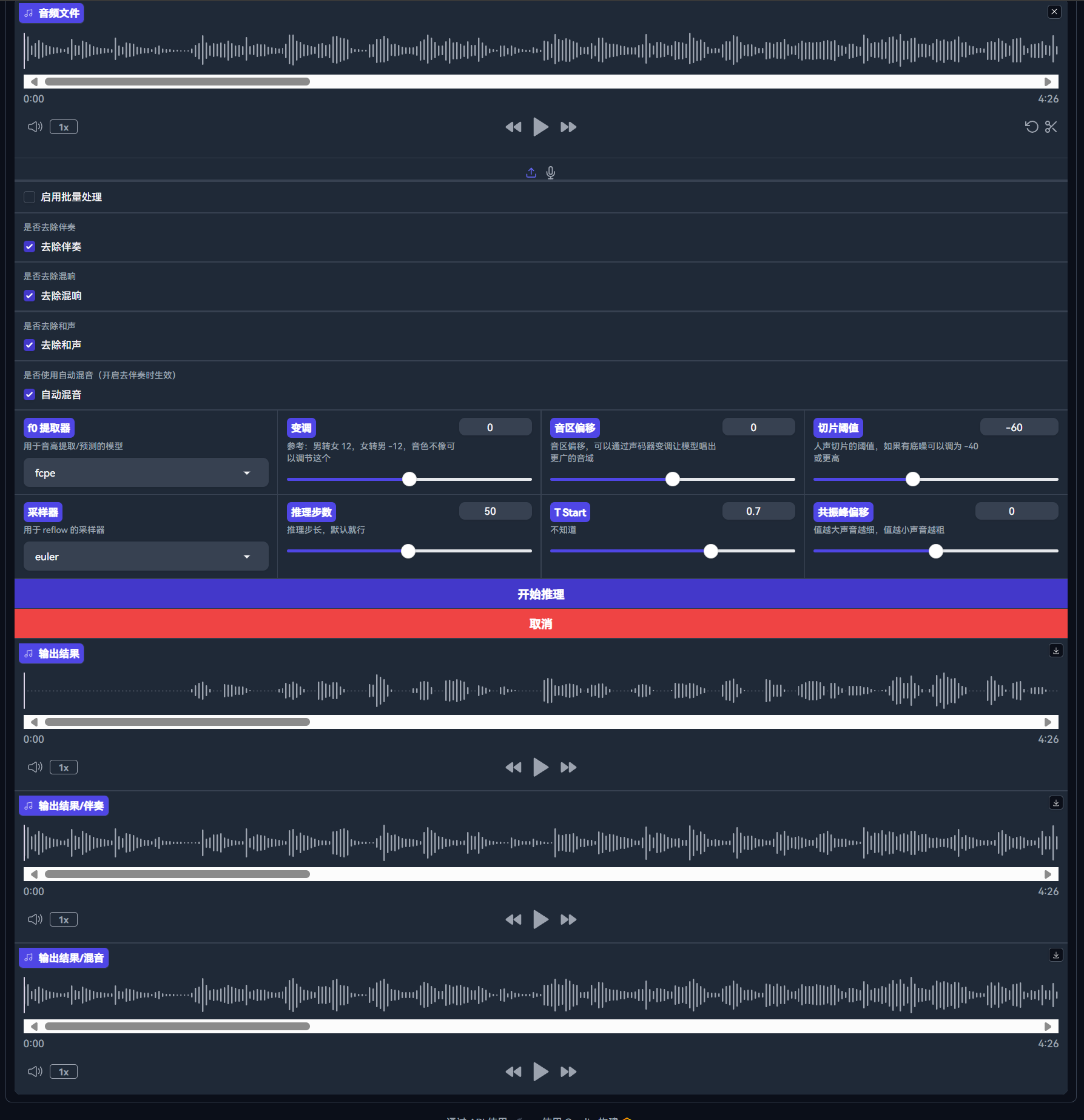
5:推理
来到推理界面
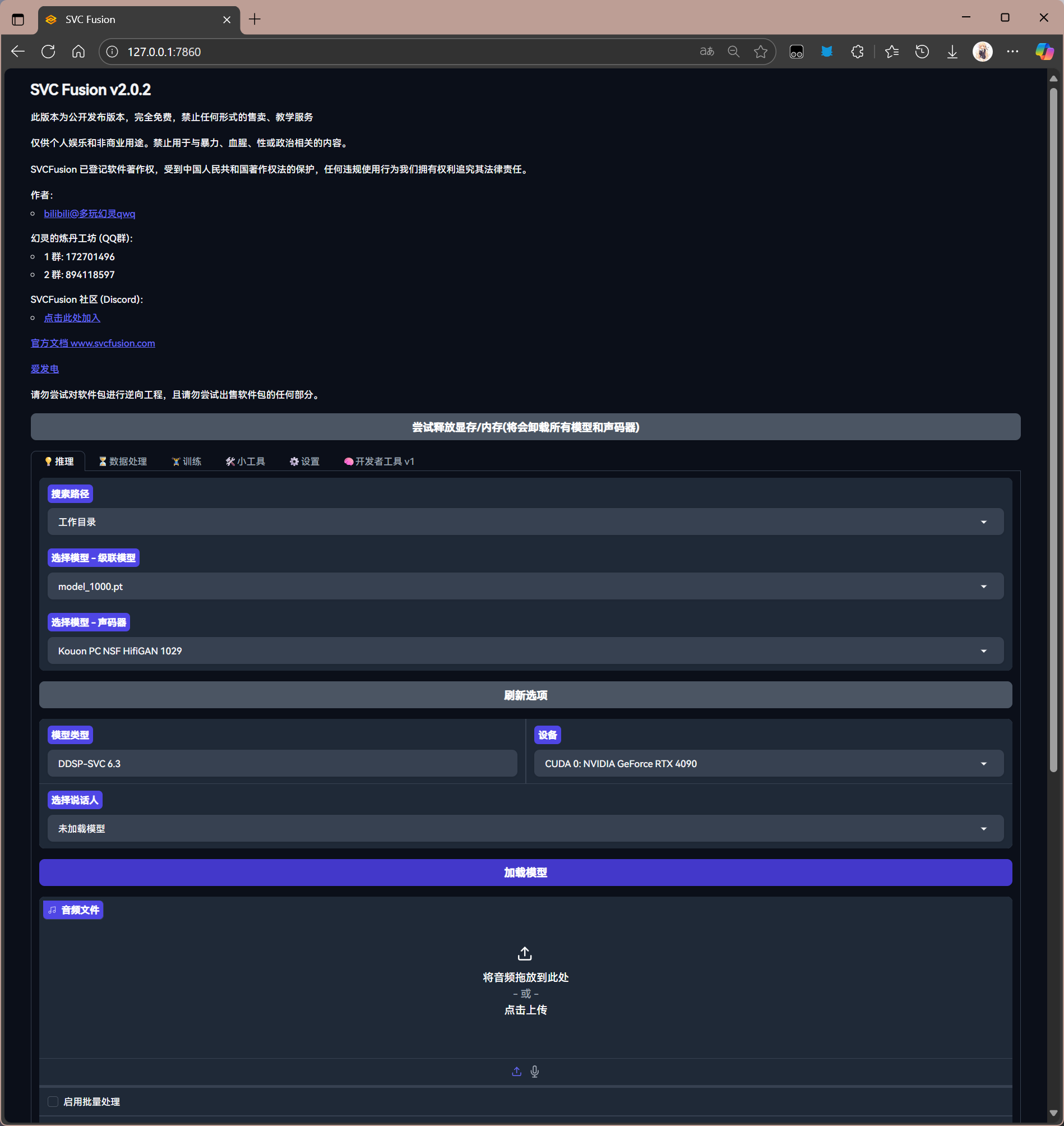
首先选择用于推理的模型

如果模型加载正常,则会显示相应的算法

接下来选择推理用的设备(优先使用 GPU)

点击选择模型进行加载

加载成功后会显示说话人

放入用于转换音色的音频文件(即推理源)
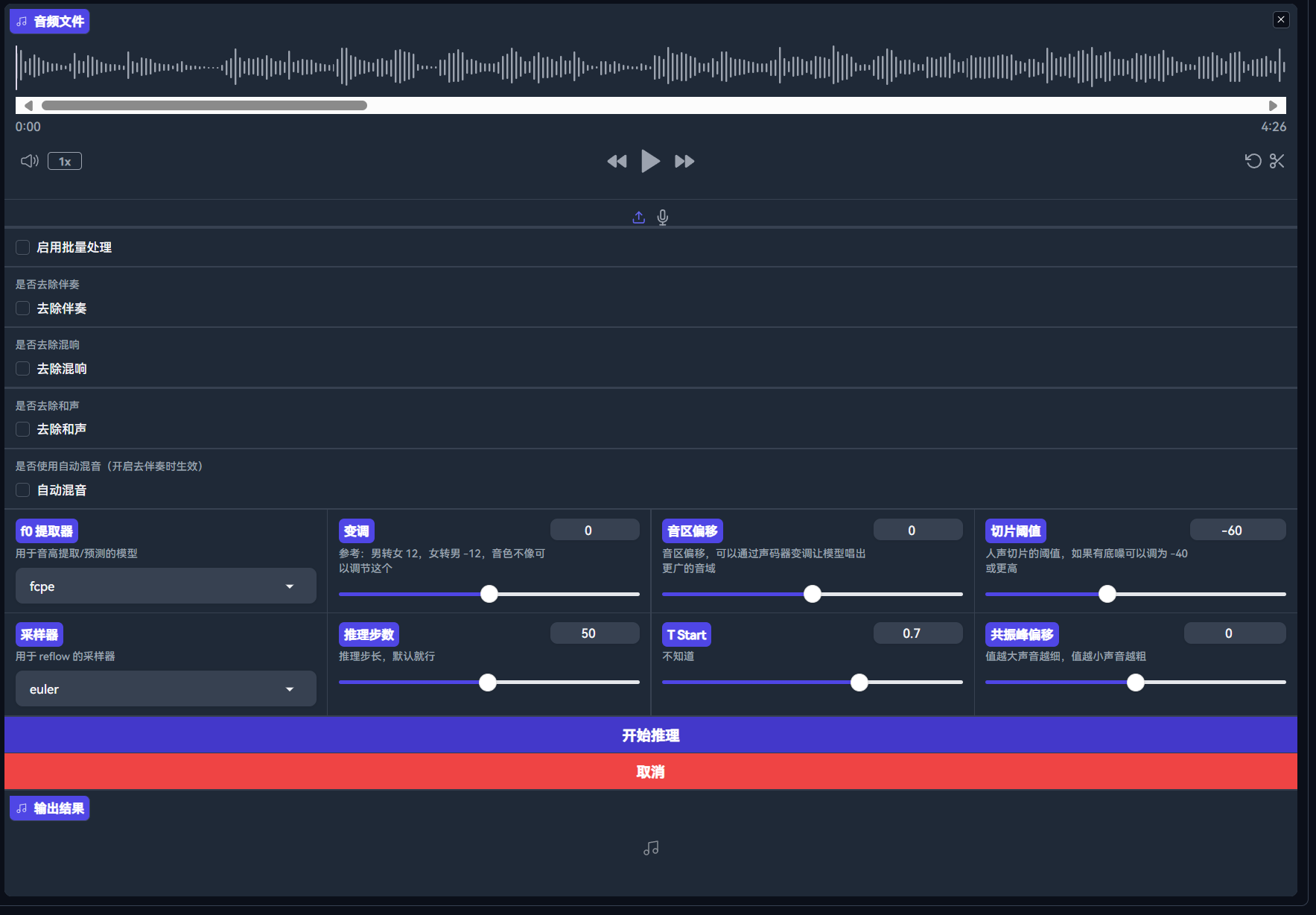
若推理源没有经过人声分离,则需要勾选去除伴奏
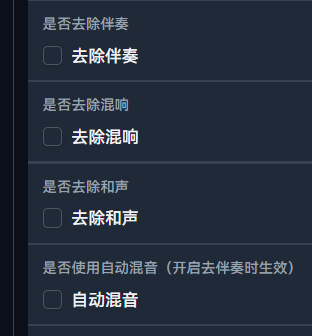
接下来选择推理参数

以下为推理参数详解:
| 参数名称 | 说明 |
|---|---|
| f0 提取器 | 用于音高提取/预测的模型,一般选择 rmvpe |
| 变调 | 每 12 为一个八度,参考:女模型转男原声 12,男模型转女原声 -12,因异性声调不同的音色泄露、失真可以调节这个 |
| 音区偏移 | 无 |
| 切片阈值 | 人声切片的阈值,如推理源有底噪可以调为 -40 或更高 |
| 采样器 | 用于 reflow 的采样器,一般默认就好 |
| 推理步数 | 推理步长,一般默认就行 |
| T Start | 控制 reflow 起点,一般默认就行 |
| 共振峰偏移 | 值越大声音越细,值越小声音越粗 |
推理完成
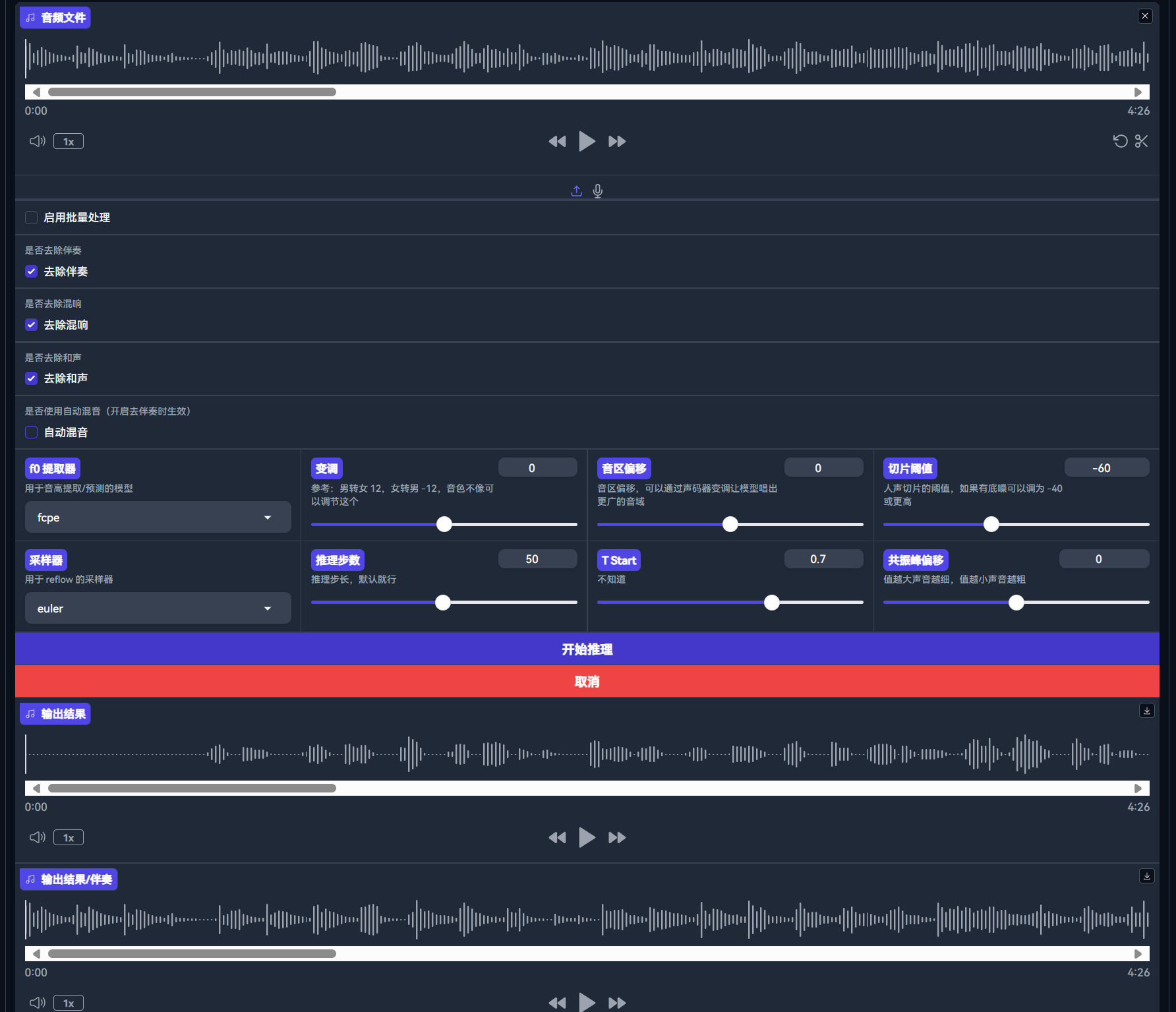
可以试听推理后的音频,并对参数进行微调
如果对音频比较满意,可以进行保存

当然也可以使用我们自带的混音功能

使用此功能需要上传未经处理的歌曲,点击“开始推理”稍等片刻即可看到结果